Pro-tip you should have done a decade ago: add a second hard drive to your machine, and put /home on it. Then during the install of the fresh OS, do not format that disk, simply mount it as /home
In a previous post, I was whining that YouTube videos were not working. I also (rather mean-spiritedly) implied that maybe Google was screwing with the connection because I was looking for ad-blocking videos. That was wrong: this fresh install of OpenSuSE has fixed that problem.
Of course, never does a single thing change, and I happened to roll over into the new month, so T-Mobile doesn’t see me as over my “unlimited” transfer limit.
But for all that testing I did, what I hadn’t tried was Windows versus Linux. I saved off a problematic YouTube link to my NextCloud Tasks, and logged in to it on a Windows machine. It played perfectly.
I don’t understand why it’s so hard to keep the list of Image Magick delegates from one version to the next.
I don’t understand why it’s so hard to find how to add the delegates that were removed during the upgrade.
Today, I need to convert a PDF to a PNG and convert -version tells me I have support for
bzlib
lzma
x
xml
zlib
none of which are image related.
Of course, this work I need to do is time-sensitive, and instead of being able to get events published to the web site for this coming weekend, I’m having debug why Image Magick is broken again.
I’m an hour in, and it’s still broken, and there’s zero information on how to fix the problem. One person said “just install from xxxx and it just works” – no, it doesn’t.
It shouldn’t take an more than an hour to convert one file from PDF to PNG.
Sometimes I hate being on OpenSuSE.
To be fair, SuSE was always more geared to be a server operating system, on which one could install a desktop environment. And with server environments, one needs to be a little more careful than with a desktop environment. If I break something on a desktop: one person (me) is affected. If I break something on a server: a thousand people are affected. So SuSE doesn’t tend to rush to implement the latest / newest thing. It also imposes defaults that are more secure (less permissive) than you might find on something else.
But apparently during the upgrade, something was reset to not allow me to execute magick filename.pdf filename.png and I’m having a damned time figuring out how to fix that. There doesn’t seem to be a README file anywhere that explains it.
New update: A little while ago, I updated my Nextcloud client on my iPhone, and a feature has been added to the “Use The App!” pop-up to turn it off. Thank you! I no longer need to mess with layout.user.php file on the server.
Log in to MySQL, and run this:
insert into oc_appconfig(appid,configkey,configvalue) values ('theming','iTunesAppId','');
There is a file in Nextcloud, layout.user.php which pushes a link to the iOS app. I wish to remove that. It will come back, every time Nextcloud pushes an update, so here is a note on how to remove it.
The file is (web root)/core/templates/layout.user.php
I don’t know if there is a setting anywhere in Nextcloud which would let me simply disable the prompt to use the app. I don’t see such; so the fallback is to edit the source code. It would be nice if there were a setting stored in the database instead. When the Nextcloud people publish an update, the recorded setting could keep the “Use The App!” prompt disabled. But I don’t think there is a setting I can get at which lets me control this.
That php code implies that the theme could have a setting; but I don’t see anything in the theme setting page for a flag of getiTunesAppId.
Mostly, I use the other pieces of Nextcloud: Calendar, Tasks, Music, and Dashboard. For those, that “Use The App!” prompt is a waste of screen real estate on a platform that doesn’t have a lot of screen real estate to waste.
I wouldn’t terribly mind if the “Use The App!” prompt showed up if I were to visit the Files part of the Nextcloud web UI: that’s the only thing the iOS app is good for. But I almost never use the Files part of Nextcloud when on mobile.
I feel a need to warn people about the following post: Although I used it for a long time and it was helpful, something changed in my environment, and now I am getting duplicate files.
For example, the song by Journey shows up twice:
"Who's Crying Now.mp3" 'Who’s Crying Now.mp3'
That second one has substituted the plain ASCII apostrophe with Unicode. Name: RIGHT SINGLE QUOTATION MARK, created as Unicode code point U+2019
Polluting my list of files with duplicates is not what I wanted.
I’ve added another option in the command line to avoid this behavior.
Another exiftool operation: suppose you have a bunch of files named something like this:
01 - String Quartet in B flat Major, 1st movement "Allegro".ogg 02 - Sonata, K. 310, 1st Movement (Mozart - Alfred Brendel).ogg 03 - Asturias_Leyenda (Albeniz - Alirio Diaz).ogg 04 - Massenet: Meditation from Thais (Mischa Elman).ogg 05 - La Coulicam - Rondement (Rameau - Harnoncourt, Lars Fryden).ogg
11 - Sonatine en trio "Modere" (Ravel - Orpheus Trio).ogg 12 - Preludes - La cathedral engloutie (Debussy - Sviatoslav Richter).ogg 13 - Eili, Eili (Mischa Elman).ogg 14 - Simple Fugue (Gr. 1, D. 1) (Bach - Gustav Leonhardt).ogg 15 - A Felicidade from Black Orpheus (Paula Robison).ogg
But really, you want the files to just be named after the Title of the song. You don’t want the leading track number, and if there are any characters in the file name that would cause Windows heartburn (like slashes, colon, asterisk, question mark, etc.), you would like those stripped out too. For example: Massenet Meditation from Thais (Mischa Elman).ogg
Here’s a handy command:
exiftool -charset Latin '-Filename<${Title;}.%le' *.mp3
So we have exiftool which is the utility that does the work. Thank you to Phil Harvey for doing the work to make this easy.
Then we have three parameters:
-charset Latin
'-Filename<${Title;}.%le'
*.mp3
The first parameter says to only use non-Unicode characters.
The third parameter says to work on files with the filename extension of .mp3
-Filename tells exiftool that it will be updating the file name. The < symbol says that the replacement for the file name will be incoming from the rest of the parameter.
After the < what follows has two pieces: ${Title;} and .%le
${Title;} is the processed text from the metadata variable Title. The leading $ and the { and } with the ; before the closing curly brace serve to strip out any invalid characters found in the title that wouldn’t work as a file name.
.%le appends a file name extension. Technically, .%e is the file name extension, but adding the l makes it lowercase. So we get the Title as the first part of the file name, and the last part of the file name is .mp3 (because we told exiftool only to look at .mp3 files).
Note that the non-change-making version is -Testname< (for testing, obviously) ↩︎
So much fun. I am glad I went. Three Dog Night was popular when I was in elementary school: they had 21 hits in the top 40 in six years (beginning in 1969). I don’t remember the words too many of their songs, but I do remember singing along to them as a kid.
Some of the songs they did were An Old Fashioned Love Song, One (is the loneliest number), Black and White, Celebrate (dance to the music), Mama Told Me (not to come), Never Been To Spain, Liar, and of course my favorite song of theirs: Joy To The World.
The guys in the band are getting pretty old, but they did seem to be having a lot of fun.
On the one hand, I want to say it was a great show. But on the other hand, I cannot ignore that the mixing was poor. Did I have fun? Yes, definitely. Would I have enjoyed it more if I could have heard the vocals clearly? Definitely.
The band did say they are working on their first new album in twenty years; they sang a song from it. It started out a cappella, and the sound was perfect. The song was beautiful in both lyrics and sound. I’m looking forward to buying the album when it comes out.
But the fact that the vocals were perfect when the mix was a cappella, and indiscernible when instruments were mixed in makes me think it was the mixing that was the problem.
The Visalia Fox Theatre has good acoustics. It is a small enough venue that booming big box echoes aren’t a problem. The theater was packed, so nice absorption. The opening act was one guy and his acoustic guitar: he sounded great. Great singer too.
So it was pretty disappointing that during the first song, I could instantly tell that the vocals were being drowned out by the background instruments.
I enjoyed the show, and I am glad that I went. But I suspect that they would have gotten a warmer reception if we could have heard them well. I’m not trying to say they got a cool reception; they did not. But I do think everyone was hoping for better sound.
• Inputs: 1.5 belts of Iron Ore, 0.5 belts of Copper Ore, 1 belt of Stone and Coal (one belt of Coal is enough to power the base*, smelters and produce all coal-required items); Petroleum Gas and Water (on either right or top side);
• 45 of Red, Green, Grey (Military) and Blue Sciences per minute (with circuit conditions countering the distance from the labs to insure no expensive science packs excess production);
• A (sorta spread-out) mall with all items you need early to pre-mid game including a big military wing with multiple Flamethrower Turrets/Explosive Cannon Shells factories and one Cliff Explosives factory;
• 15 Labs to fit the Lab Research Speed 2 research speed requirement;
• Only four Red Underground Belts needed at the very later stage of base building (Blue Science and Explosive Cannon Shells factories), no Red Belts needed up to that point;
• An empty 4×4 zone in the middle of the base for a Roboport to be placed later, covering up most of the chests with produced materials;
Assuming that you are currently in the subdirectory with music files, and those files are of type .ogg and you want to create a playlist file named _great.m3u which contains the names of the songs with “World of Warcraft” in the album name, this one liner creates such a file:
-p '$filename' prints the file name. We later strip off the other stuff by redirecting stderr to null. That’s the 2> /dev/null part.
-if '$album =~ /World of Warcraft/' and -if '$artist =~ /E.S. Posthumus/' are matches against a regular expression. =~ says we are doing a match and the text between the slashes are what need to be present for the match to report true.
> _great.m3u overwrites the existing file, but then >> _great.m3u appends to it.
Care to guess who purchased the collector’s editions of some of the games so I could get a CD of the game music (or files from Steam)?
One thing (I don’t know that it’s a problem, really) is that Artist =~ /E.S. Posthumus/ will find the same file as Genre =~ /Classical/ so the same songs end up in the playlist twice. Maybe I just like E.S. Posthumus so much that I want their chance of being picked by the shuffler better than average. 😉
But if that’s not your bag, this will make a new file (with a new name) which contains only unique song file names:
Now Firefox won’t let me log in. I’m going to have to factory reset the router, configure it all over again, and this time leave it configured for clear text only.
This seems like going backward.
I mean, I get it: it is clear that RC4 is too easily broken, so support for it was removed.
But I’m not so wealthy that I want to just throw away an otherwise fine – old – router. I put the latest version of Tomato on it that still runs on that platform; but, that version of firmware is from 2010.
This is for my Internet of Things network. Nothing on that network is going to be terribly fast, so I certainly don’t need a high powered router. Still, if a lightbulb gets compromised, I’d like there to be at least a tiny bit of work involved in capturing the router’s password. RC4 may be brute forced in minutes with a GPU, but a lightbulb doesn’t have that sort of processing power.
Anyway, I goofed up. I saw an article about how to convert the web admin interface to use https only, so I pushed the button to generate a new certificate. Now I’m locked out and have to wipe the router back to factory reset.
The official error message is: Error code: SSL_ERROR_NO_CYPHER_OVERLAP
Thank you smarter people than me, for not allowing an override, even temporarily. Thank you smarter people than me, for making sure my IoT wireless access point web admin interface password has to remain in clear, plain text, forever.
This was difficult, so I will provide a How-To here. The goal was to put port 8 on my switch on VLAN 4084. This is my Internet of Things (IoT) VLAN.
A prerequisite of course, is that the downlink from the router to the switch has the VLAN 4084 tag in it. For me, that will be port 1 on the switch.
Another PITA is that the Trendnet EdgeSmart switch self configures to 192.168.10.200 – and that is hard-coded. After you get a machine directly connected to it (with a static IP address), then you can configure the switch to use DHCP to put it on your main LAN. But if you find that you want to factory reset to start over, you’re going to have to go back to the static IP config on 192.168.10.x. The MAC address doesn’t show up in the router until after the DHCP inspired reboot, so you have no idea of what the new web admin interface IP address is. After the switch has rebooted, then you can go in to the DHCP leases and find out what the new IP address is. I don’t know that I would have bothered, except that the laptop I was using has a little smaller screen, and the Trendnet web interface is primitive. I could not get decent screen shots on it because of the primitive web page rendering, so I needed to access it from a bigger screen, which meant making it available on my main LAN, which meant DHCP. But I digress.
What I’m trying to get to:
End result is 802.1q VLAN tagging on downlink port 1 and no tagging on port 8
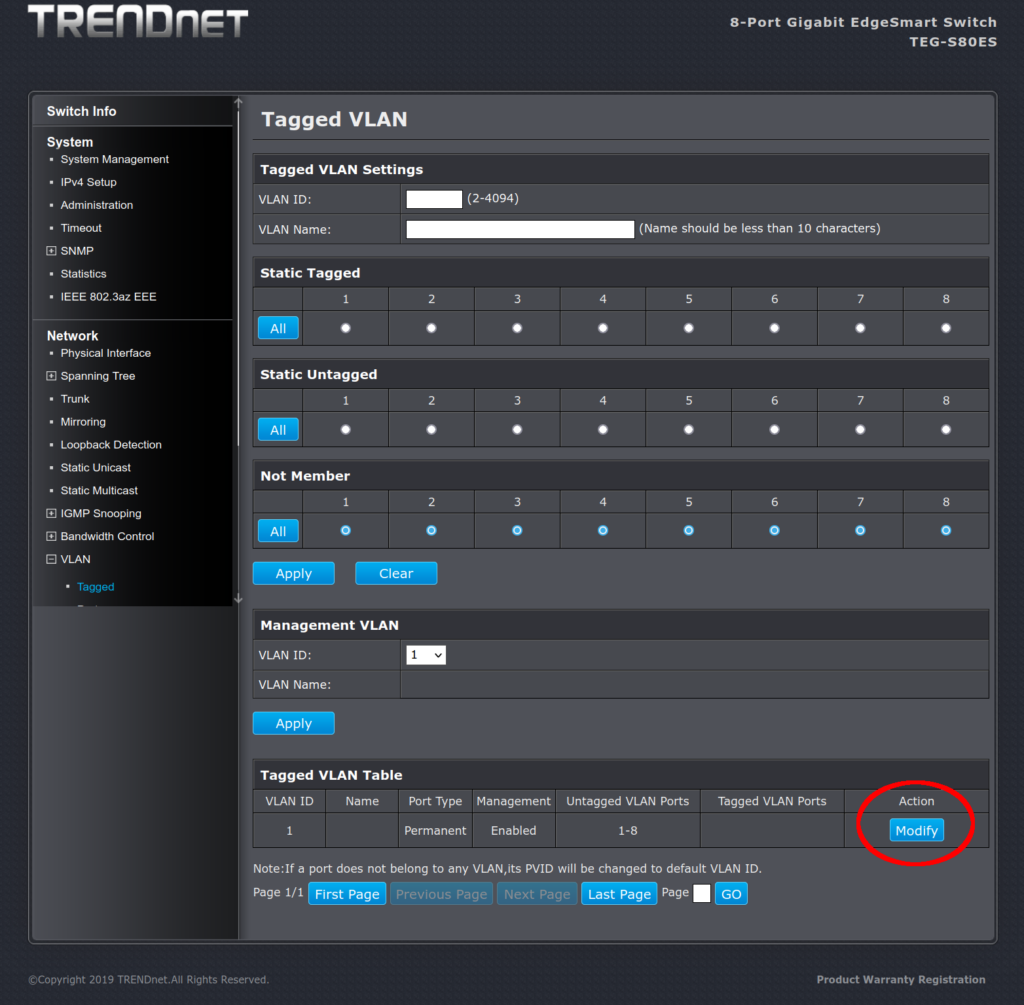
First step: Modify VLAN ID 1
Here is what the web admin page looks like after a factory reset:
After factory reset, you have only VLAN 1 on all ports – but no tagging anywhere
VLAN ID 1 is the default VLAN. But if you never turned on VLANs, it would never have mattered. The default configuration (out of the box) is that if a frame with that VLAN tag were to show up on the switch, all the ports on the switch would strip that tag out (“un” tagging) before putting the frame on the wire of the ports. However, port 8 is a member of VLAN 1. That would cause us trouble later.
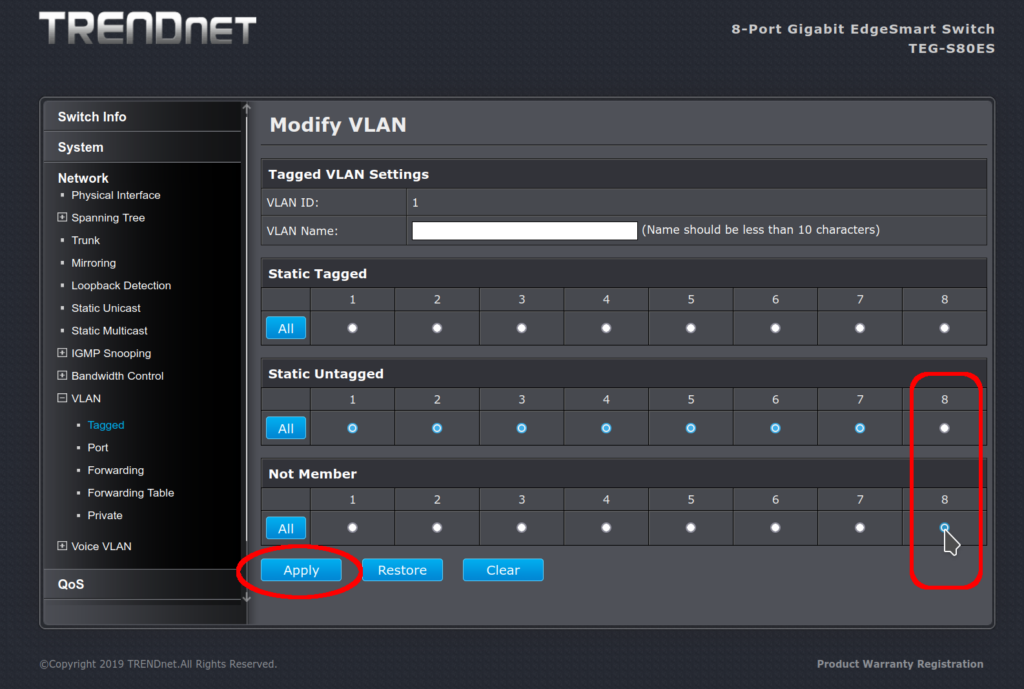
On the VLAN ID 1 modify page, we want to set this:
First, on VLAN 1, move port 8 to not-a-member away from static untagged
First, we move VLAN 1 to not-a-member away from static untagged for port 8. Then we apply the change. This will free up port 8 to be assigned a different VLAN later.
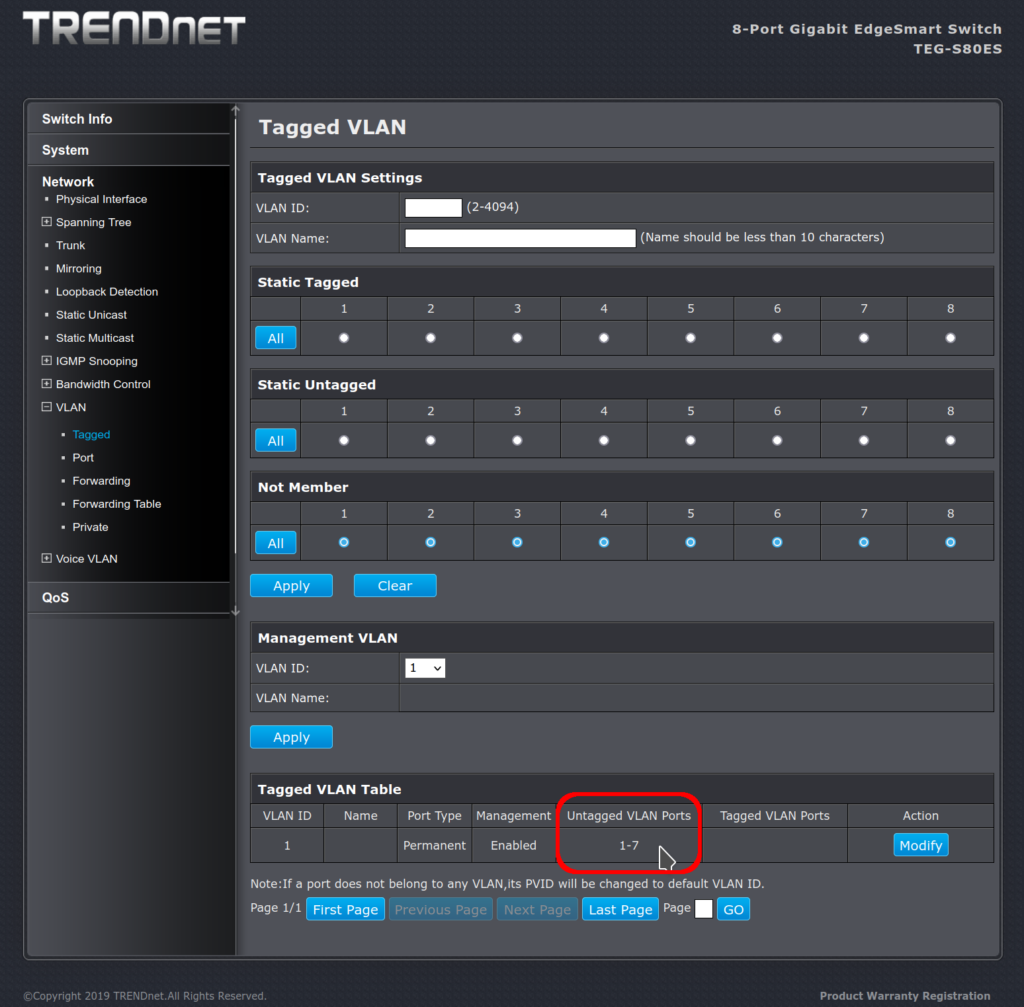
What it looks like after:
VLAN ID 1 untagged ports are 1-7 leaving port 8 available
I may be overly sensitive here; but this is a terrible user interface. If I didn’t know better, I would think that the top part (which is really for adding a new VLAN) was telling me the current status of the ports. It is not. But it looks like all the ports are in the not-a-member group. They used a whole bunch of screen real estate to not show me what the actual status is, but what it could be if I were to proceed. I wonder if putting the “Tagged VLAN Table” at the top would be better, and not showing the grid layout of port assignments at all until someone clicked Modify or View.
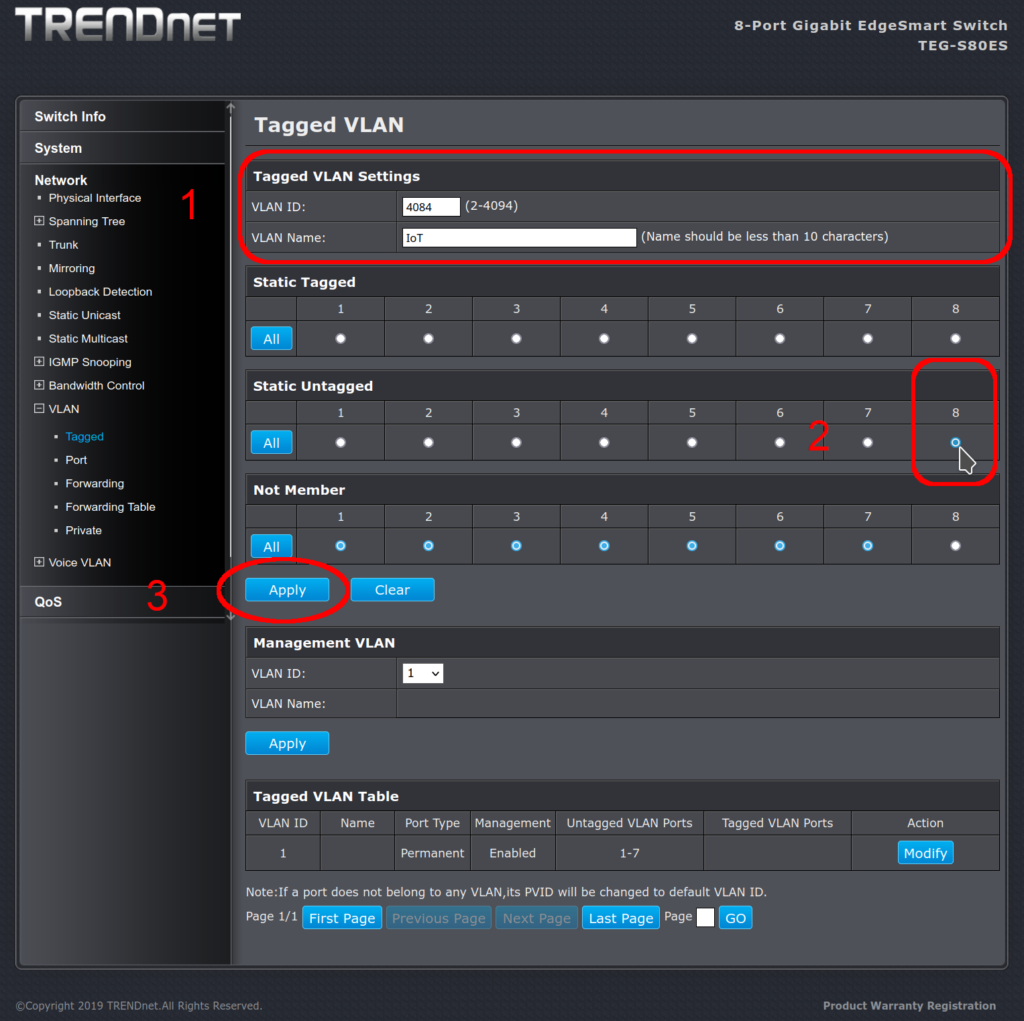
Second step: adding the new VLAN
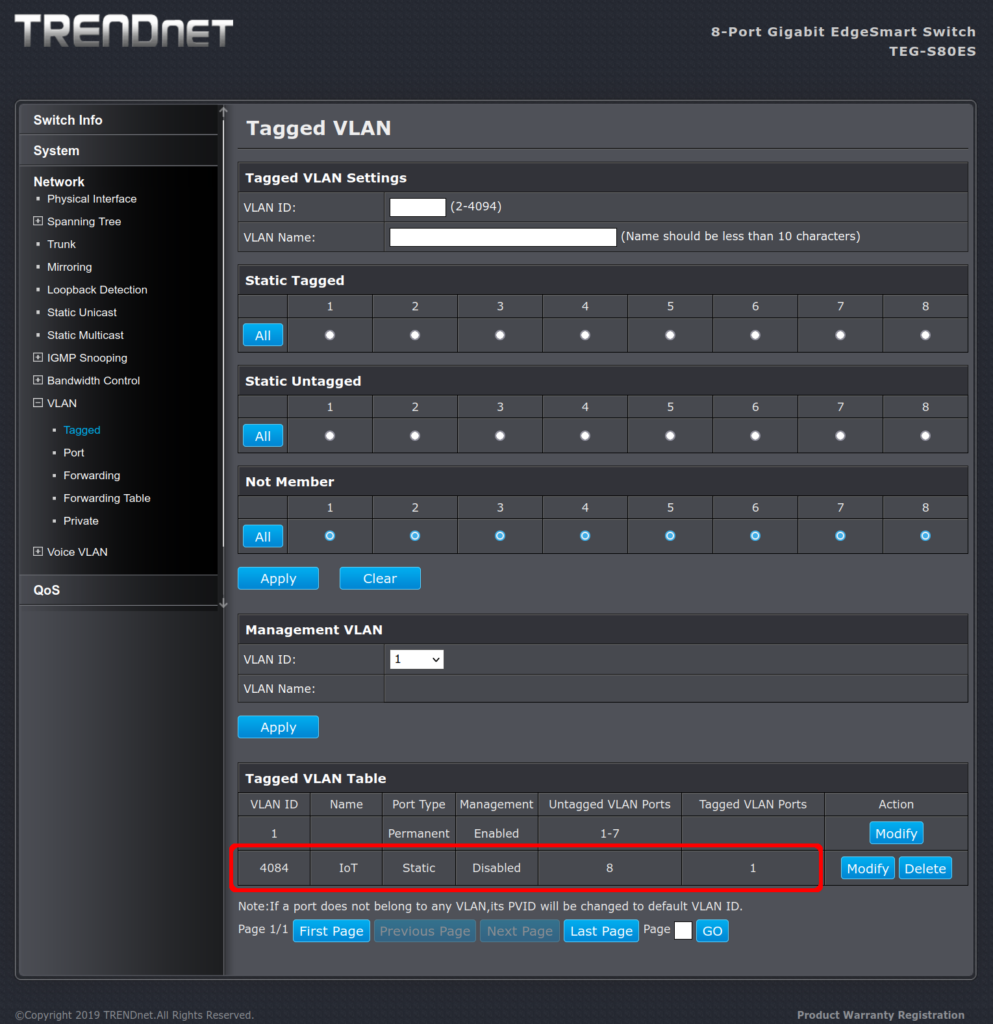
Now we can add our VLAN 4084 with port 8 assigned:
On the main web admin screen, create the new VLAN and assign it
So I typed 4084 into the VLAN ID field, added the descriptive name, then clicked in the Static Untagged section on port 8, and then clicked Apply. This gave me the screen below. Note that we are not done yet.
This was the problem: the web interface uses what looks like radio buttons, so the idea that seems to be presented is that clicking on Static Untagged port 8 should move the port from VLAN 1 to VLAN 4084. But attempting to click on port 8: Static Untagged did nothing.
Behind the scene, port 8 was still a member of VLAN 1, so the admin interface would not assign Static Untagged to port 8 in VLAN 4084. It was super frustrating that clicking on port 8 static untagged did nothing: no errors, no warning – just a refusal to work with no response or feedback at all. I could put port 8 in the static tag membership, but those frames would (likely) not be understood by the IoT device. Although the interface showed me the radio button, I could not put port 8 in the Static Untagged membership. A better developed interface would have prompted me with something like “Assigning this port to Untagged will remove VLAN 1”. Okay, do that. Please.
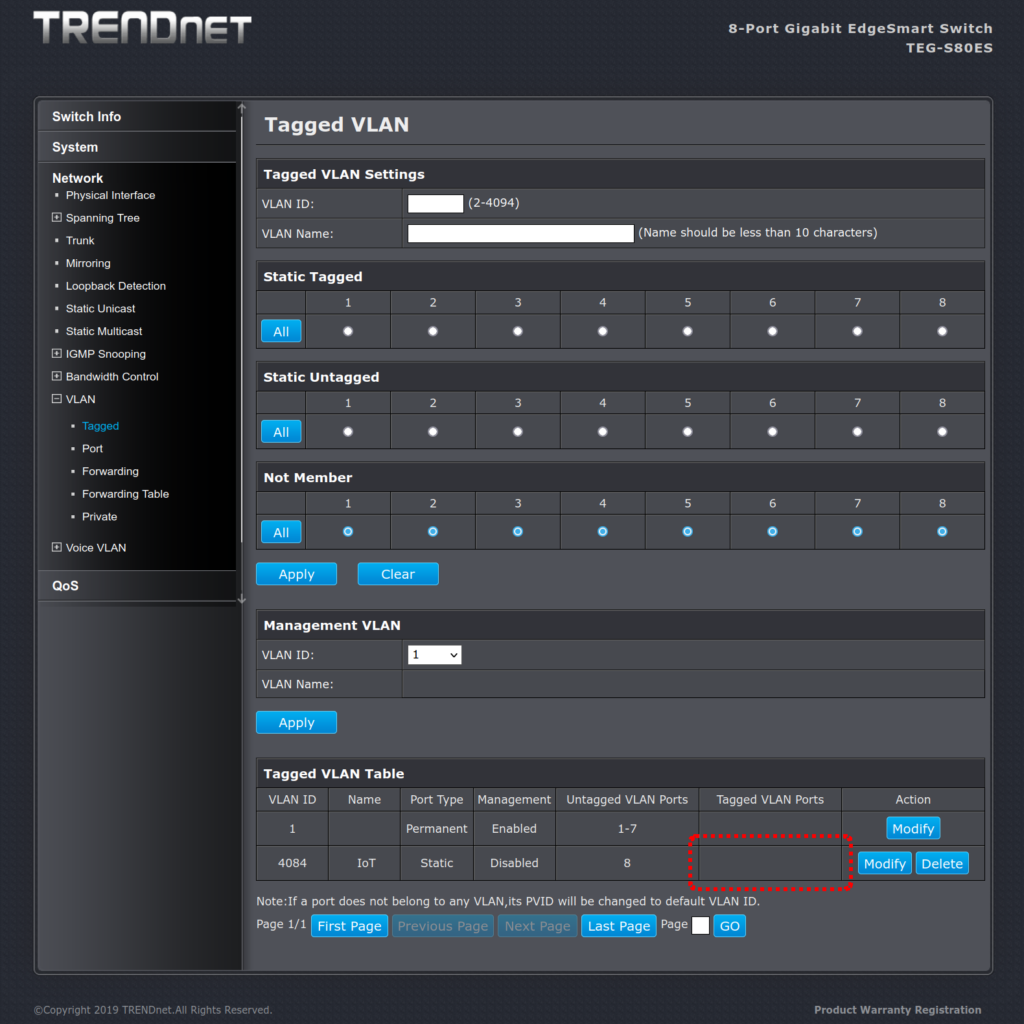
We’re almost there. The configuration will now look like this:
VLAN 4084 is defined and will present on port 8 (once it gets there)
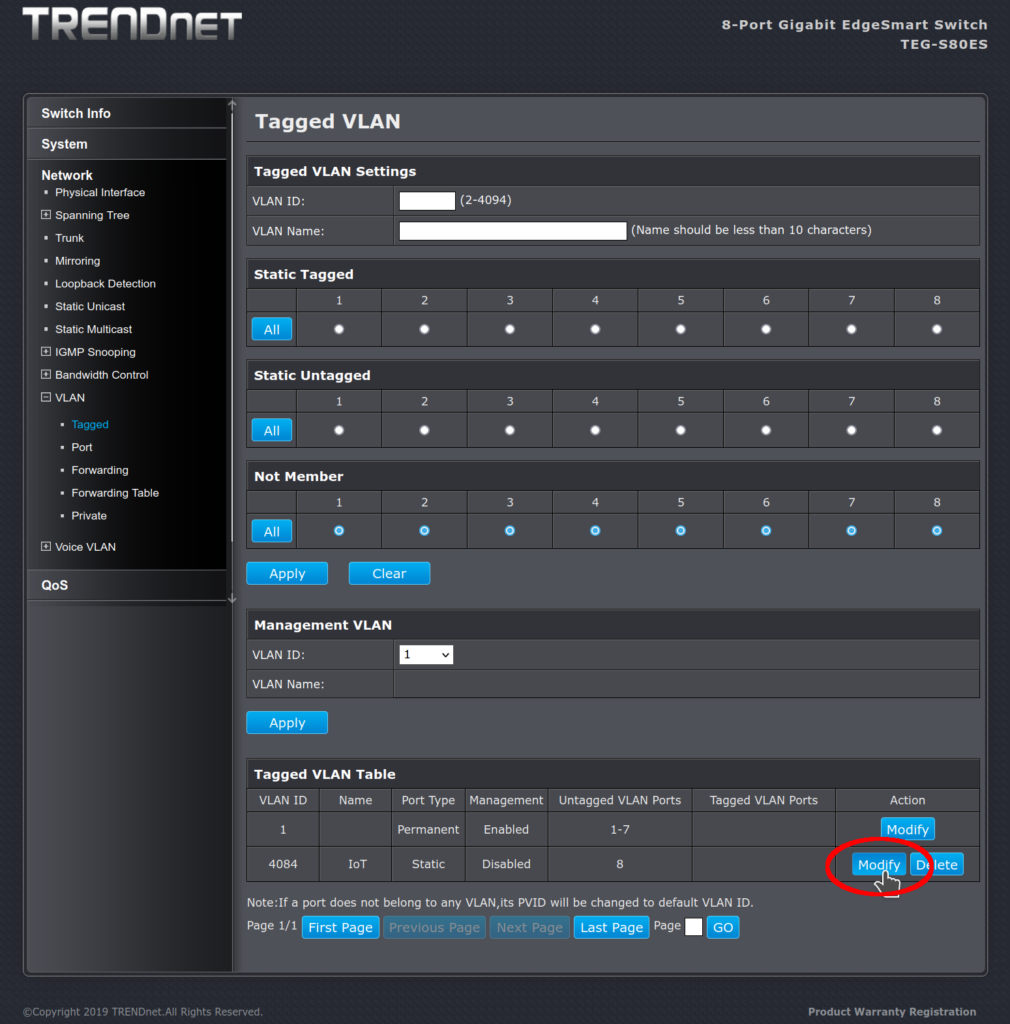
Step 3: add the trunk to the uplink port
Modify VLAN 4084:
Modify VLAN 4084
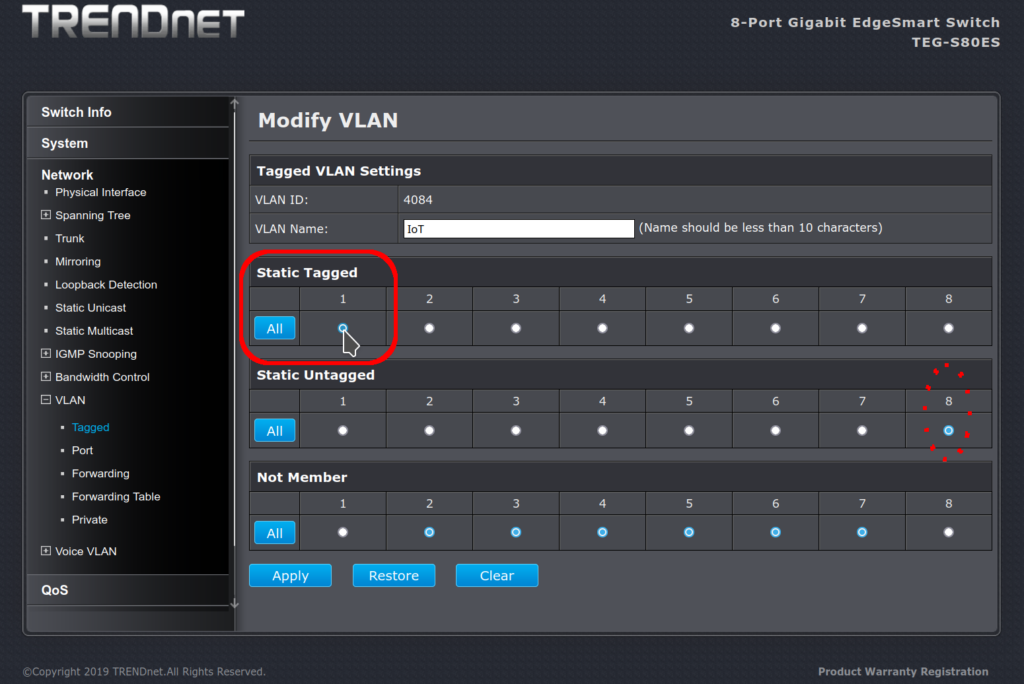
Make the modification: frames to port 1 should be tagged with VLAN 4084. This is because I chose port 1 as the uplink port. The uplink is the trunk connection to the core of the network. But when the switch presents the frame on port 8, the tags should be stripped off (“un” tagged):
VLAN 4084: port 1 tagged, port 8 untagged
Apply our changes, save the configuration, and reboot the device on port 8.
If our VLAN 4084 is otherwise configured correctly, our IoT device should now be on the IoT VLAN. Enjoy.
As painful as this was, I wish I’d bought something else with a better web admin interface than these Trendnet switches. Ultimately, they worked, but man I wasted a lot of hours trying to get them to work. That was four hours of my life I’m not getting back. I should have spent the extra $15 for a switch with software / documentation that doesn’t suck.